Finding the Diameter of an N-Ary Tree: the "To-And-Thru" approach
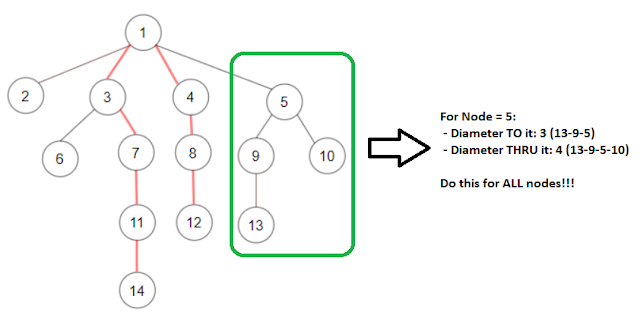
Hello folks, this is a problem that exemplifies a technique that I like to call the To-And-Thru. We want to find the diameter of an N-ary tree (meaning a tree where each node has 0, 1 or more children). Take a look: https://leetcode.com/problems/diameter-of-n-ary-tree/ What you want is a near-linear solution in the number of nodes. If you assume that the tree has N nodes, and that each node has an average of LogN children, then the To-And-Thru algorithm below will run in O(N * (LogN)^2) time. Not really linear, but something that seems to be closer to NLogN. The idea is the following: Post-Order DFS For each node, compute the following: The longest path TO the node The longest path THRU the node The above computation will take LogN*LogN since there are two nested loops ( I guess there might be a way to reduce this to LogN, meaning one loop ) As you compute 2.1 and 2.2, your diameter will be the Max See figure below. Works well enough. Code is down below, stay safe, stay motivated!!! A